Here is the previous exam from 2015, note that the course material has changed a bit since that time.
- Comment
- Reblog
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
Here is the previous exam from 2015, note that the course material has changed a bit since that time.

These are our answers for the Question 1, Exam 2015:
a) Weight vector gets closer to the optimal weight vector?
No, there is no guarantee to reach the actual global minima (the weight vector can get stuck in local minima)
b) Loss gets better on every step?
No, the loss isn’t necessarily convex : by escaping some local minima, we can get to a point in another local minima with a higher loss.
c) Will eventually reach the weight vector that gives the smallest possible loss value?
No, same as above : we can get stuck in local minima instead of global minima (since this is not necessarily a convex function).
d) Number of mistakes on the training data never increases?
No, we train on a loss function and not the classification accuracy. An update of the weight vector may reduce the cost function over the entire dataset, but there is no guarantee that each of the training data points will be better classified.
Do you get the same results/better explanations?
LikeLike
I have the same results, but I would explain it this way :
a) Since the loss landscape is not convex in general, the weight vector can be stuck in every local minimum between its initial value and the optimal value (depending on the loss curvature etc..), and the loss landscape can exhibit local minima that are very far from the global one.
d) I think that if a given update decreases the loss, there is indeed no guarantee that each of the training data points will be better classified, but there is still a guarantee that the number of well classified points increases !
I think that a better explanation would be the case where the loss increases, which can happen only if the optimization algorithm is able to escape local minima, and reaches a higher local minima.
But standard SGD cannot do this, right ? It can only go towards the opposite direction of the gradient.. So the answer should be yes !?
(This would change the answer to b) too)
LikeLike
I think wath is unclear is what mean “learning rate small enough for practical purposes, but not so small that the network doesn’t learn”. What does “learn” mean? Does it mean
1) that we go from local minima to local minima (and escape the bad local minimas)
or
2) that we stay in our initial local minima (like a ball rolling down)?.
In the first option, then the answer at a)b)c) stays no.
In the second option, then the answer at b) changes to yes.
d) I think the batch gradient descent (whole training set) can escape a local minima for a higher minima (if the learning rate is big enough to escape local minimas) by overshooting (can happen for every learning rate, depending on the slope)
However, in both options, there is no guarantee that the number of mistakes never increases, since the cross-entropy is only an approximation of the training accuracy.
For example, let’s say we have 2 data points x1 and x2 with class labels 0 and 1, respectively.
Epoch t : Model classify x1 as a 0 with 51% confidence and misclassify x2 as a 0 with 100% confidence (so 0% confidence on the right class). Then the loss associated with x2 will be very high.
Epoch t+1 : Model misclassify x1 as a 1 with 51% confidence (49% confidence on the right class) and still misclassify x2 as a 0, but with 60% confidence (40% confidence on the right class). The loss associated with x2 will decrease a lot, probably more than the loss associated with x1.
The total loss would have decrease between those 2 epochs (since the right class label confidence changed from 51% and 0% at epoch t to 51% and 60% at epoch t+1), but the number of mistakes increased.
LikeLike
I agree that it is unclear whether the learning rate is large enough to escape local minima or not. So the answer to b) depends on the optimization algorithm / its parameters and on the loss landscape, though in general we can assume the latter to be highly non-convex.
As for d), you’re right !
LikeLike
Je suis un peu confus avec les questions a) et b)
par contre :
c) Non . En effet on a aucune garantie de converger vers la plus petite fonction de coût possible. on peut tres bien converger vers un optimum local.
d) Non : En effet le nombre d’erreurs de classification n’apparait en aucun moment dans notre fonction objective et on ne peut donc avoir une garantie sur la direction et l’amplitude apres chaque mise a jour.
a) puisque on parle de tendre vers un des vecteurs, s’il en existe plusieurs, ma reponse est alors Oui, en effet on fait une analyse locale et meme si on ne tend pas vers le minimum global, on tend vers le minimum dans cette region locale ( cependant qu’en est-il si c’est un Saddle Point ?)
LikeLike
a) La question était de savoir si le vecteur de paramètres tendait vers le vecteur de paramètres optimal (associé au minimum global). Puisque le vecteur de paramètres peut tendre vers un vecteur de paramètres uniquement “localement optimal”, alors on n’a aucune garantie qu’il s’approche du vecteur de paramètres globalement optimal. (même chose que pour le c) )
LikeLike
Compare and contrast (providing specific differences, advantages and disadvantages) the
following optimization algorithms : Adagrad, RMSprop, Adadelta.
Adagrad adapts the learning rate individually for each network parameter. This adaptation is done by accumulating the square of all historical gradient values for each parameter and making the learning rate of each parameter inversely proportional to the square root of their sum. While this provides faster convergence in convex optimization problems, this scaling can actually result in decreasing the learning rate prematurely in a deep learning setting. RMSprop fixes this problem by using only an exponentially decaying weighted average of previous gradiend values. However that introduces an extra hyper parameter.
Not sure if we talked about Adadelta.
(b) What are the differences between standard Momentum and Nesterov Momentum ?
In Nesterov momentum the gradient is evaluated after the velocity is applied to the parameters, compared to standard Momentum when it is evaluated before. In a convex case Nesterov momentum decreases the steps needed to converge however in non-convex cases it does not make a difference.
At this point I have a question about Adagrad. How exactly does adagrad make it faster to converge in a convex setting? How does lowering the learning rate associated with the parameters having the highest gradient achieve something like this?
LikeLike
Here is a nice review of all the optimization algorithms, including Adadelta :
http://sebastianruder.com/optimizing-gradient-descent/index.html#adadelta
As for Adagrad, I think it leads to faster convergence in a convex setting because by adapting the learning rate at each step it smoothly converges to the minimum instead of ‘jumping around’.
LikeLike
Hi everyone !
I have created a folder that regroup several exams from the previous years. I don’t know if it will be relevant for the exam but it can be a good practice though !
folder : https://www.dropbox.com/sh/f6t35tmfa85iur5/AADg1uRnSZ9JSZffAWgaCu-ta?dl=0
Good luck !
LikeLiked by 1 person
Answer for Exam2015, Question 4.
I am not fully convinced by my answers. Do you get better explanations?
a) Derive conditional distributions p(x | y, z), p(y |x,z) and p(z|x,y)
Simliar to what was seen in class/slides :
p(xi=1 | y,z) = sigmoid(W[i,:] * y + U[i,:] * z + a)
p(yi=1 | x,z) = sigmoid(x * W[:,i] + V[i,:] * z + b)
p(zi=1 | x,y) = sigmoid(x * U[:,i] + y * V[:,i] + c)
b) Describe efficient method of sampling from the joint distribution (description + justification)
I don’t understand how we could sample from the joint probability if there is no visible variables, so let’s suppose x and y are visible variables and z is a hidden variable.
Then we can procede by Gibbs sampling:
1- Sample z ~ p(z | x,y)
2- Sample y ~ p(y | x,z) (with z = the new sampled variable at step 1)
3- Sample x ~ p(x | y,z) (with y and z sampled at steps 1 and 2)
Efficient because all the variables in x are independant so we can sample simultaneously from p(x | y,z). Same for y and z.
However, it wasn’t specified that x and y were visible variables… how do we sample if they are not?
c) Posterior distribution p(z,y|x) tractable or intractable? Given x is a visible variable.
I am not sure, but my guess would be intractable, since there is a product between y and z. But I don’t fully understand why it’s a problem.. Any idea?
d) Model amenable to learning via contrastive divergence (CD) ?
If my answer at c) is correct, and x is the only visible variable, then no (since the sampling is intractable). But I don’t know if there exist some approximation or something…
LikeLike
Concerning Q1 I have the same results
In Q2, effectively I think we have to suppose that it is p(x|y,z) and not a joint distribution because it will be impossible to generate from the joint in my opinion
In Q3, it is intractable. You can see it on the course slides (DBM – Slide 5). As you said, because of the term y^T*V*z we cannot evaluate p(y,z|x). Indeed, to evaluate y you need to know V*z and to evaluate z you need to know y^t*V. This two Random Variables are then conditionally dependent
In Q4, since Q3 says it’s intractable, you cannot use CD ans especially Gibbs Sampling … Take a look a DBM – Slide 5, where it is said that an other method to evaluate the approximate posterior in to use variational mean field approximation
I’m not sure if these are the correct answers, but the course indicates these explanations !
LikeLike
I think those are good answers. I talked with Aaron for Q2.
We must sample using the conditionals p(z|x,y), p(x|y,z), p(y|x,z) (to maintain the tractability) but there is no reason why 2 of those variables should be visible.
In the first step (Sample z ~ p(z | x,y) ), if only x is a visible variable, then y would be initially sampled from a random distribution in order to use the conditionals, and then we would continue the sampling as explained above.
LikeLiked by 1 person
Your answers for Q1a) are for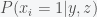 , however I believe we are looking for the full distribution
, however I believe we are looking for the full distribution  . Your answer is an evaluation of the distribution!
. Your answer is an evaluation of the distribution!
You probably have the right answer on your notes if you got there though :). I still think the distinction is important!
LikeLiked by 1 person
Yes, you are right. The answer should be p(x|y,z) =product over i of p(xi=1 |y,z), where p(xi=1|y,z) as specified above.
LikeLike
Does anyone has an idea for the answer of Question 2 ii) (CNNs) of the quiz ?
LikeLike
Have a look at http://distill.pub/2016/deconv-checkerboard/
LikeLiked by 1 person
Was the question meant to address the artifact issue? I am not sure I get that from the question. Similarly to Julian I am rather confused by this question. My first thought was the fact the weights were shared between the encoder and decoder that could come screw things up..
LikeLike